Section 7.7 is entitled “Determinants.”
The question being answered this section is, “If we are
given a matrix A, how do we know if its nullspace is nontrivial?” (I know; this
is the question you’ve been asking since the beginning of nullspace.)
Before we answer this question, I’m going to warn you up
front that the book just jumps into the idea of determinants pretty quickly. For
example, the book literally says you’re supposed to recognize the determinant
of a 2 × 2 matrix without any indication that we went over this. At least, from
the sections I’ve had the pleasure (and displeasure) of reading in this journey
through differential equations, I haven’t seen the determinant of a 2 × 2
matrix come up yet.
So I guess I’m trying to say that if you didn’t recognize
determinants, even though the book apparently thinks you should, then that’s
fine. If I wasn’t concurrently enrolled in a linear algebra class, I would be
super confused about that idea as well.
Just for notation’s sake, the shorthand for “the determinant
of A” is det(A). Now I feel much better about jumping into 7.7. At least, I
feel less awkward about unfairly throwing unknown notation and equations and
such things into your face.
Anyway, I’ll get onto the math words now.
Suppose A is a matrix where

Its determinant (which you’re just supposed to recognize) is
ad – bc. Then A is nonsingular if and only if det(A) ≠ 0. In fact,
this proposition is true for any square matrix.
If A is a square matrix, then the homogeneous equation Ax = 0 has a nonzero solution if and only if det(A) = 0. Then, to answer
our original question, A will have a nontrivial nullspace if and only if the
determinant of A is 0.
Moving on, for a 3x3 matrix A:

The determinant has the more complicated form det(A) = a11a22a33
– a11a23a32 – a12a21a33
+ a12a23a31 – a13a22a31
+ a13a21a32.
For a definition of determinant, let’s first look at one of
the products when we looked at det(A) 3x3, let’s say a13a21a32.
The first subscripts are (1, 2, 3) and the second subscripts are (3, 1, 2).
They’re the same 3 numbers, but they’re rearranged. If you look at all the
products, you will see this is the case for all of them.
Determinants in higher dimensions also have this form. We need
to notate some things before going to the definition.
“A permutation of the first n integers is a list σ of these
integers in any order” (323).
When we consider the 3x3 matrix, σ = (3, 1, 2) is
a permutation of the first three integers.
Since a permutation is just a list of numbers, if we wanted
to know how many permutations there are for 3 numbers, then we would have 6
different permutations for n = 3. (For any n, the number of permutations is n!
(as in n factorial), so if you want to find the number of permutations, you
could always do it that way. For n = 3, the number of permutations would be
3x2x1 = 6, which is what is in the book.)
These different permutations are (1, 2, 3), (1, 3, 2), (2,
1, 3), (2, 3, 1), (3, 1, 2), and (3, 2, 1). If you look back at our formula for
the determinant of A, you’ll see these six different permutations are all
present, with some minus signs thrown in.
So how do we know when to throw in a minus sign, and when to
not throw in a minus sign? Well, when you’re looking at a permutation, say (3,
1, 2), then you have a number of interchanges you can make to transform this
into a standard, ordered list of numbers. For example,

Then the book goes onto to say it’s remarkable that the
number of interchanges needed for this operation is always even or always odd.
It’s…remarkable? I wasn’t aware the number of interchanges
could be anything else besides even or odd.
 |
| Breaking news: the number of interchanges can either be even, odd, or bread. I can has math grant now? |
Thus, the permutation is even if the number of interchanges
is even, and the permutation is odd if the number of interchanges is odd. For
example, (4, 2, 1, 3) would be even, while (4, 2, 3, 1) is odd. Conclusively,
we will define a permutation σ

And now, the moment you’ve all been waiting for.
“The determinant of the matrix

is defined to be

where the sum is over all permutations of the first n
integers” (324).
The actual definition isn’t going to be that helpful in
calculating determinants, considering that the number of permutations for n = 4
is 4! = 24 permutations. That gets tedious and ridiculous very quickly. Therefore,
we will almost never use the definition to compute a determinant.
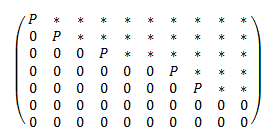
The exception to this rule is an upper or lower triangular
matrix. (http://en.wikipedia.org/wiki/Triangular_matrix#Description)
To save you from tedious work, you would use the summation and see that the
determinant of an upper or lower triangular matrix is the product of its
diagonal elements.
Some properties concerning determinants:
If A is a square matrix, and B is a matrix obtained from a
multiple of one row to another of A, then their determinants will be equal.
Similarly, if you swap two rows of A and call that resulting matrix B, then
det(B) = -det(A). Finally, you obtained matrix B by multiplying a row of A by
some constant c, then det(B) = c·det(A).
If matrix A has two equal columns, then its determinant is
zero. Similarly, if A has two equal rows, then det(A) = 0.
Something neat about the transpose of A and A: det(AT)
= det(A).
Now, you might be wondering how you actually compute the
determinant of a matrix if using the definition sucks. Well, you do something
called expansion. You can expand on a row or a column. This is best shown by an
example (and an exciting example, since I can make this one up and not
experience deadly consequences. I mean, I can’t just make up an inverse
example. The inverses of matrices go downhill very quickly when you just put
random numbers wherever you feel like).
Before the example, let’s show some more summations.
If you want to expand on the ith row of a matrix, where 1 ≤ i ≤ n, then

If you want to expand on the jth column of a matrix, where 1 ≤ j ≤ n, then

For example, consider the 3 × 3 matrix

Let’s expand on row and a column, just for the example’s
sake.
If we expand on the third row, then we would have

If we expand on the second column, we would have

Notice we get the same answer for our row and column
expansion. That’s nifty, right?
Finally, here are some more properties concerning
determinants:
If A and B are n × n matrices, then det(AB) = det(A)det(B).
If A is a nonsingular matrix, then det(A-1) =
1/det(A).
“A collection of n
vectors x1, x2, … , xn in Rn
is a basis for Rn if and
only if the matrix X = [x1,
x2, … , xn], whose column vectors
are the indicated vectors, has a nonzero determinant” (328).
All right, that’s all chapter 7 has to offer you! The math
is over now, so if you don’t want to read on about my struggles through this
chapter (and why it was up so quickly), then just stop reading here and I’ll
see you for chapter 8.
I’ll just let you know right now, I’m trying to get ahead of
the game. As you already knew, I’m doing this blog only for the cookies (and
for the selfless act of sharing said cookies with my differential equations
class). I get points for each summary I post, and I get more points if my
summary is released before we discuss that section in class. Well, I was very
ahead once I had finished the summary for section 4.1, and that was exciting
and all.
Then my instructor emailed me and told me that I was looking
at the incorrect schedule and I needed to follow the weekly schedule. I
shrugged my shoulders and moved onto doing the summaries for sections 6.1, 6.2,
and 7.1. I was still ahead of the lecture, so I felt pretty good.
Then my instructor completely skipped over chapter 6 and he
got dangerously close to catching up to my summaries.
It’s been slightly frustrating, and I’ve had a minor
headache all week (since I’ve had homework, tests, and work/band things to
attend to), but I’m hoping that by getting all of chapter 7 done this week,
I’ll be ahead enough to not be rushing all of the time.
In other words, I’ve been rushing this week so I don’t have to
rush ever again.
I’ll see you in chapter 8.